| Designing Secure Software by Loren Kohnfelder (all rights reserved) |
|---|
| Home 00 01 02 03 04 05 06 07 08 09 10 11 12 13 14 Appendix: A B C D |
| Buy the book here. |
“The threat is usually more terrifying than the thing itself.” —Saul Alinsky
Threats are omnipresent, but we can live with them if we manage them. Software is no different, except that we don’t have the benefit of millions of years of evolution to prepare us. That is why you need to adopt a software security mindset, which requires you to flip from the builder’s perspective to that of the attackers. Understanding the potential threats to a system is the essential starting point in order to bake solid defenses and mitigations into your software designs. But to perceive these threats in the first place, you’ll have to stop thinking about typical use cases and using the software as intended. Instead, you must simply see it for what it is: a bunch of code and components, with data flowing around and getting stored here and there.
For example, consider the paperclip: it’s cleverly designed to hold sheets of paper together, but if you bend a paperclip just right, it’s easily refashioned into a stiff wire. A security mindset discerns that you could insert this wire into the keyhole of a lock to manipulate the tumblers and open it without the key. It’s worth emphasizing that threats include all manner of ways that harm occurs. Adversarial attacks conducted with intention are an important focus of the discussion, but this does not mean that you should exclude other threats due to software bugs, human error, accidents, hardware failures, and so on.
Threat modeling provides a perspective with which to guide any decisions that impact security throughout the software development process. The following treatment focuses on concepts and principles, rather than any of the many specific methodologies for doing threat modeling. Early threat modeling as first practiced at Microsoft in the early 2000s proved effective, but it required extensive training, as well as a considerable investment of effort. Fortunately, you can do threat modeling in any number of ways, and once you understand the concepts, it’s easy to tailor your process to fit the time and effort available while still producing meaningful results.
Setting out to enumerate all the threats and identify all the points of vulnerability in a large software system is a daunting task. However, smart security work targets incrementally raising the bar, not shooting for perfection. Your first efforts may only find a fraction of all the potential issues, and only mitigate some of those: even so, that’s a substantial improvement. Just possibly, such an effort may avert a major security incident—a real accomplishment. Unfortunately, you almost never know of the foiled attacks, and that absence of feedback can feel disappointing. The more you flex your security mindset muscles, the better you’ll become at seeing threats.
Finally, it’s important to understand that threat modeling can provide new levels of understanding of the target system beyond the scope of security. Through the process of examining the software in new ways, you may gain insights that suggest various improvements, efficiencies, simplifications, and new features unrelated to security.
The Adversarial Perspective
“Exploits are the closest thing to ‘magic spells’ we experience in the real world: Construct the right incantation, gain remote control over device.” —Halvar Flake
Human perpetrators are the ultimate threat; security incidents don’t just happen by themselves. Any concerted analysis of software security includes considering what hypothetical adversaries might try in order to properly defend against potential attacks. Attackers are a motley group, from script kiddies (criminals without tech skills using automated malware) to sophisticated nation-state actors, and everything in between. To the extent that you can think from an adversary’s perspective, that’s great, but don’t fool yourself into thinking you can accurately predict their every move or spend too much time trying to get inside their heads, like a master sleuth outsmarting a wily foe. It’s helpful to understand the attacker’s mindset, but for our purposes of building secure software, the details of actual techniques they might use to probe, penetrate, and exfiltrate data are unimportant.
Consider what the obvious targets of a system might be (sometimes, what’s valuable to an adversary is less valuable to you, or vice versa) and ensure that those assets are robustly secured, but don’t waste time attempting to read the minds of hypothetical attackers. Rather than expend unnecessary effort, they’ll often focus on the weakest link to accomplish their goal (or they might be poking around aimlessly, which can be very hard to defend against since their actions will seem undirected and arbitrary). Bugs definitely attract attention because they suggest weakness, and attackers who stumble onto an apparent bug will try creative variations to see if they can really bust something. Errors or side effects that disclose details of the insides of the system (for example, detailed stack dumps) are prime fodder for attackers to jump on and run with.
Once attackers find a weakness, they’re likely to focus more effort on it, because some small flaws have a way of expanding to produce larger consequences under concerted attack (as we shall see in Chapter 8 in detail). Often, it’s possible to combine two tiny flaws that are of no concern individually to produce a major attack, so it’s wise to take all vulnerabilities seriously. And attackers definitely know about threat modeling, though they are working without inside information (at least until they manage some degree of penetration).
Even though we can never really anticipate what our adversaries will spend time on, it does make sense to consider the motivation of hypothetical attackers as a measure of the likelihood of diligent attacks. Basically, this amounts to a famous criminal’s explanation of why he robbed banks: “Because that’s where the money is.” The point is, the greater the prospective gain from attacking a system, the higher the level of skill and resources you can expect potential attackers to apply. Speculative as this might be, the analysis is useful as a relative guide: powerful corporations and government, military, and financial institutions are big targets. Your cat photos are not.
In the end, with all kinds of violence, it’s always far easier to attack and cause harm than to defend. Attackers get to choose their point of entry, and with determination they can try as many exploits as they like, because they only need to succeed once. All of which amounts to more reasons why it’s important to prioritize security work: the defenders need every advantage available.
The Four Questions
Adam Shostack, who carried the threat modeling torch at Microsoft for years, boils the methodology down to Four Questions:
- What are we working on?
- What can go wrong?
- What are we going to do about it?
- Did we do a good job?
The first question aims to establish the project’s context and scope. Answering it includes describing the project’s requirements and design, its components, and their interactions, as well as considering operational issues and use cases. Next, at the core of the method, the second question attempts to anticipate potential problems, and the third question explores mitigations to those problems we identify. (We’ll look more closely at mitigations in Chapter 3, but first we will examine how they relate to threats.) Finally, the last question asks us to reflect on the entire process—what the software does, how it can go wrong, and how well we’ve mitigated the threats—in order to assess the risk reduction and confirm that the system will be sufficiently secure. Should unresolved issues remain, we go through the questions again to fill in the remaining gaps.
There is much more to threat modeling than this, but it’s surprising how far simply working from the Four Questions can take you. Armed with these concepts, and in conjunction with the other ideas and techniques in this book, you can significantly raise the security bar for the systems you build and operate.
Threat Modeling
“What could possibly go wrong?”
We often ask this question to make a cynical joke. But asked unironically, it succinctly expresses the point of departure for threat modeling. Responding to this first question requires us to identify and assess threats; we can then prioritize these and work on mitigations that reduce the risk of the important ones.
Let’s unpack that previous sentence. The following steps outline the basic threat modeling process:
- Work from a model of the system to ensure that we consider everything in scope.
- Identify assets within the system that need protection.
- Scour the system model for potential threats, component by component, identifying attack surfaces (places where an attack could originate), assets (valuable data and resources), trust boundaries (interfaces bridging more-trusted parts of the system with the less-trusted parts), and different types of threats.
- Analyze these potential threats, from the most concrete to the hypothetical.
- Rank the threats, working from the most to least critical.
- Propose mitigations to reduce risk for the most critical threats.
- Add mitigations, starting from the most impactful and easiest, and working until we start receiving diminishing returns.
- Test the efficacy of the mitigations, starting with those for the most critical threats.
For complex systems, a complete inventory of all potential threats will be enormous, and a full analysis is almost certainly infeasible (just as enumerating every conceivable way of doing anything would never end if you got imaginative, which attackers often do). In practice, the first threat modeling pass should focus on the biggest and most likely threats to the high-value assets only. Once you’ve understood those threats and put first-line mitigations in place, you can evaluate the remaining risk by iteratively considering the remaining lesser threats that you’ve already identified. From that point, you can perform one or more additional threat modeling passes as needed, each casting a wider net, to include additional assets, deeper analysis, and more of the less likely or minor threats. The process stops when you’ve achieved a sufficiently thorough understanding of the most important threats, planned the necessary mitigations, and deemed the remaining known risk acceptable.
People intuitively do something akin to threat modeling in daily life, taking what we call common-sense precautions. To send a private message in a public place, most people type it instead of dictating it aloud to their phones. Using the language of threat modeling, we’d say the message content is the information asset, and disclosure is the threat. Speaking within earshot of others is the attack surface, and using a silent, alternative input method is a good mitigation. If a nosy stranger is watching, you could add an additional mitigation, like cupping the phone with your other hand to shield the screen from view. But while we do this sort of thing all the time quite naturally in the real world, applying these same techniques to complex software systems, where our familiar physical intuitions don’t apply, requires much more discipline.
Work from a Model
You’ll need a rigorous approach in order to thoroughly identify threats. Traditionally, threat modeling uses data flow diagrams (DFDs) or Unified Modeling Language (UML) descriptions of the system, but you can use whatever model you like. Whatever high-level description of the system you choose, be it a DFD, UML, a design document, or an informal “whiteboard session,” the idea is to look at an abstraction of the system, so long as it has enough granularity to capture the detail you need for analysis.
More formalized approaches tend to be more rigorous and produce more accurate results, but at the cost of additional time and effort. Over the years, the security community has invented a number of alternative methodologies that offer different trade-offs, in no small part because the full-blown threat modeling method (involving formal models like DFDs) is so costly and effort-intensive. Today, you can use specialized software to help with the process. The best ones automate significant parts of the work, although interpreting the results and making risk assessments will always require human judgment. This book tells you all you need to know in order to threat model on your own, without special diagrams or tools, so long as you understand the system well enough to thoroughly answer the Four Questions. You can work toward more advanced forms from there as you like.
Whatever model you work from, thoroughly cover the target system at the appropriate resolution. Choose the appropriate level of detail for the analysis by the Goldilocks principle: don’t attempt too much detail or the work will be endless, and don’t go too high-level or you’ll omit important details. Completing the process quickly with little to show for it is a sure sign of insufficient granularity, just as making little headway after hours of work indicates your model may be too granular.
Let’s consider what the right level of granularity would be for a generic web server. You’re handed a model consisting of a block diagram showing “the internet” on the left, connected to a “frontend server” in the center with a third component, “database,” on the right. This isn’t helpful, because nearly every web application ever devised fits this model. All the assets are presumably in the database, but what exactly are they? There must be a trust boundary between the system and the internet, but is that the only one? Clearly, this model operates at too high a level. At the other extreme would be a model showing a detailed breakdown of every library, all the dependencies of the framework, and the relationships of components far below the level of the application you want to analyze.
The Goldilocks version would fall somewhere between these extremes. The data stored in the database (assets) would be clumped into categories, each of which you could treat as a whole: say, customer data, inventory data, and system logs. The server component would be broken into parts granular enough to reveal multiple processes, including what privilege each runs at, perhaps an internal cache on the host machine, and descriptions of the communication channels and network used to talk to the internet and the database.
Identify Assets
Working methodically through the model, identify assets and the potential threats to them. Assets are the entities in the system that you must protect. Most assets are data, but they could also include hardware, communication bandwidth, computational capacity, and physical resources, such as electricity.
Beginners at threat modeling naturally want to protect everything, which would be great in a perfect world. But in practice, you’ll need to prioritize your assets. For example, consider any web application: anyone on the internet can access it using browsers or other software that you have no control over, so it’s impossible to fully protect the client side. Also, you should always keep internal system logs private, but if the logs contain harmless details of no value to outsiders, it doesn’t make sense to invest much energy in protecting them. This doesn’t mean that you ignore such risks completely; just make sure that less important mitigations don’t take away effort needed elsewhere. For example, it literally takes a minute to protect non-sensitive logs by setting permissions so that only administrators can read the contents, so that’s effort well spent.
On the other hand, you could effectively treat data representing financial transactions as real money and prioritize it accordingly. Personal information is another increasingly sensitive category of asset, because a knowledge of a person’s location or other identifying details can compromise their privacy or even put them at risk.
Also, I generally advise against attempting to perform complex risk-assessment calculations. For example, avoid attempting to assigning dollar values for the purpose of risk ranking. To do this, you would have to somehow come up with probabilities for many unknowables. How many attackers will target you, and how hard will they try, and to do what? How often will they succeed, and to what degree? How much money is the customer database even worth? (Note that its value to the company and the amount an attacker could sell it for often differ, as might the value that users would assign to their own data.) How many hours of work and other expenses will a hypothetical security incident incur?
Instead, a simple way to prioritize assets that’s surprisingly effective is to rank them by “T-shirt sizes”—a simplification that I find useful, though it’s not a standard industry practice. Assign “Large” to major assets you must protect to the max, “Medium” to valuable assets that are less critical, and “Small” to lesser ones of minor consequence (usually not even listed). High-value systems may have “Extra-Large” assets that deserve extraordinary levels of protection, such as bank account balances at a financial institution, or private encryption keys that anchor the security of communications. In this simple scheme, protection and mitigation efforts focus first on Large assets, and then opportunistically on Medium ones. Opportunistic protection consists of low-effort work that has little downside. But even if you can secure Small assets very opportunistically, defend all Large assets before spending any time on these. Chapter 13 discusses ranking vulnerabilities in detail, and much of that is applicable to threat assessment as well.
Consider the following unusual but easy-to-understand example, in which actual money serves as a resource for protecting an asset. When you connect a bank account to PayPal, the website must confirm that it’s your account. At this stage, you already have an account, and they know your verified email address, but now they need to check that you are the lawful owner of a certain bank account. PayPal came up with a clever solution to this challenge, but it costs them a little money. The company deposits a random dollar amount into the bank account that a new user claims to own. (Let’s say the deposit amount is between $0.01 and $0.99, so the average cost is $0.50 per customer.) Inter-bank transfers allow them to deposit money to any account without preauthorization, because literally the worst that can happen is that someone gets a mysterious donation into their account. After making the deposit, PayPal requests that you tell them the amount of the deposit, which only the account owner can do, and treats a correct answer as proof of ownership. While PayPal literally loses money through this process, paying staff to confirm bank account ownership would be slower and more costly, so this makes a lot of sense.
Threat Modeling PayPal’s Account Authentication
Try threat modeling the bank account authentication process just described (which, for the purposes of this discussion, is a simplification of the actual process, about which I have no detailed information). For example, notice that if you opened 100 fake PayPal accounts and randomly guessed a deposit amount for each, you would have a decent chance of getting authenticated once. At that point, you would have taken over the account. How could PayPal mitigate that kind of attack? What other attacks and mitigations can you come up with?
Here are some aspects of the analysis to help you get started. For the threat of massive guessing, you could put in place a number of restrictions to force adversaries to work harder: allow only one attempt to set up a bank account every day from the same account, and restrict new account creations from the same computer (as identified by IP address, user agent, and other fingerprints). Such restrictions are called rate limiting, and ideally the enforced delay should grow with repeated attempts (so that, for example, after the second failed attempt the attacker must wait a week to try again).
There’s a subtlety in this process, because you must balance user convenience and security. If the user just types in their bank information and requests validation, a typo could require them to retry the process, which, for honest customers, means that rate limiting needs to be fairly lax. So, you should consider ways of reducing error when entering bank details in order to keep the rate limiting strict without losing customers who just can’t type. One way to do this is to ask them to enter the bank info twice, and only proceed if the entries match. That works, but it’s more work and lazy people might give up, which means losing a good customer. Perhaps a better way to do it, legal issues aside, is to ask the customer to upload a photo of a voided check. The system would recognize the printed bank info, then display it for the customer to confirm, thereby virtually eliminating any chance for errors.
But what if, after using this system for years, somebody discovers a series of successful attacks? Perhaps patient thieves waited out the rate limiting, and it turns out that the 1-in-99 odds of guessing right aren’t enough to stop them. All other things being equal, PayPal could raise the dollar amount of the “free money” deposit to a maximum of $3 or $5 or more, but at some point (probably an actuary could tell you the exact break-even point), the monetary cost of deposits is going to exceed the value of new customer acquisition.
In that case, the company would have to consider an entirely different approach. Here’s one idea, and I invite readers to invent others: new customer setup could be handled via video by a live customer support agent. Simply having to face a real person is going to intimidate a lot of attackers in the first place. The agent could ask to see a bank statement or similar evidence and authorize on the spot. (Please note: this is a simplified example, not an actual business suggestion.)
The assets you choose to prioritize should probably include data, such as customer resources, personal information, business documents, operational logs, and software internals, to name just a few possibilities. Prioritizing protection of data assets considers many factors, including information security (the C-I-A triad discussed in Chapter 1), because the harms of leaking, modification, and destruction of data may differ greatly. Information leaks, including partial disclosures of information (for example, the last four digits of a credit card number), are tricky to evaluate, because you must consider what an attacker could do with the information. Analysis becomes harder still when an attacker could join multiple shards of information into an approximation of the complete dataset.
If you lump assets together, you can simplify the analysis considerably, but beware of losing resolution in the process. For example, if you administer several of your databases together, grant access similarly, use them for data that originates from similar sources, and store them in the same location, treating them as one makes good sense. However, if any of these factors differ significantly, you would have sufficient reason to handle them separately. Make sure to consider those distinctions in your risk analysis, as well as for mitigation purposes.
Finally, always consider the value of assets from the perspectives of all parties involved. For instance, social media services manage all kinds of data: internal company plans, advertising data, and customer data. The value of each of these assets differs depending on if you are the company’s CEO, an advertiser, a customer, or perhaps an attacker seeking financial gain or pursuing a political agenda. In fact, even among customers you’ll likely find great differences in how they perceive the importance of privacy in their communications, or the value they place on their data. Good data stewardship principles suggest that your protection of customer and partner data should arguably exceed that of the company’s own proprietary data (and I have heard of company executives actually stating this as policy).
Not all companies take this approach. Facebook’s Beacon feature automatically posted the details of users’ purchases to their news feeds, then quickly shut down following an immediate outpouring of customer outrage and some lawsuits. While Beacon never endangered Facebook (except by damaging the brand’s reputation), it posed a real danger to customers. Threat modeling the consequences of information disclosure for customers would have quickly revealed that the unintended disclosure of purchases of Christmas or birthday presents, or worse, engagement rings, was likely to prove problematic.
Identify Attack Surfaces
Pay special attention to attack surfaces, because these are the attacker’s first point of entry. You should consider any opportunity to minimize the attack surface a big win, because doing so shuts off a potential source of trouble entirely. Many attacks potentially fan out across the system, so stopping them early can be a great defense. This is why secure government buildings have checkpoints with metal detectors just inside the single public entrance.
Software design is typically much more complex than the design of a physical building, so identifying the entire attack surface is not so simple. Unless you can embed a system in a trusted, secure environment, having some attack surface is inevitable. The internet always provides a huge point of exposure, since literally anyone anywhere can anonymously connect through it. While it might be tempting to consider an intranet (a private network) as trusted, you probably shouldn’t, unless it has very high standards of both physical and IT security. At the very least, treat it as an attack surface with reduced risk. For devices or kiosk applications, consider the outside portion of the box, including screens and user interface buttons, an attack surface.
Note that attack surfaces exist outside the digital realm. Consider the kiosk, for example: a display in a public area could leak information via “shoulder surfing.” An attacker could also perform even subtler side-channel attacks to deduce information about the internal state of a system by monitoring its electromagnetic emissions, heat, power consumption, keyboard sounds, and so forth.
Identify Trust Boundaries
Next, identify the system’s trust boundaries. Since trust and privilege are almost always paired, you can think in terms of privilege boundaries if that makes more sense. Human analogs of trust boundaries might be the interface between a manager and an employee, or the door of your house, where you choose who to let inside.
Consider a classic example of a trust boundary: an operating system’s kernel/userland interface. This architecture became popular in a time when mainframe computers were rare and often shared by many users. The system booted up the kernel, which isolated applications in different userland process instances (corresponding to different user accounts) from interfering with each other or crashing the whole system. Whenever userland code calls into the kernel, execution crosses a trust boundary. Trust boundaries are important, because the transition into higher-privilege execution is an opportunity for bigger trouble.
| Trust vs. Privilege |
|---|
| In this book I’ll be talking about high and low privilege as well as high and low trust, and there is great potential for confusion since they are very closely related and difficult to separate cleanly. The inherent character of trust and privilege is such that they almost invariably correlate: where trust is high, privilege is also usually high, and vice versa. Beyond the scope of this book, it’s common for people to use these expressions (trust versus privilege) interchangeably, and generously interpreting them however makes best sense to you without insisting on correcting others is usually the best practice. |
The SSH secure shell daemon (sshd(8)) is a great example of secure design with trust boundaries. The SSH protocol allows authorized users to remotely log in to a host, then run a shell via a secure network channel over the internet. But the SSH daemon, which persistently listens for connections to initiate the protocol, requires very careful design because it crosses a trust boundary. The listener process typically needs superuser privileges, because when an authorized user presents valid credentials, it must be able to create processes for any user. Yet it must also listen to the public internet, exposing it to the world for attack.
To accept SSH login requests, the daemon must generate a secure channel for communication that’s impervious to snooping or tampering, then handle and validate sensitive credentials. Only then can it instantiate a shell process on the host computer with the right privileges. This entire process involves a lot of code, running with the highest level of privilege (so it can create a process for any user account), that must operate perfectly or risk deeply compromising the system. Incoming requests can come from anywhere on the internet and are initially indistinguishable from attacks, so it’s hard to imagine a more attractive target with higher stakes.
Given the large attack surface and the severity of any vulnerability, extensive efforts to mitigate risk are justified for the daemon process. Figure 2-1 shows a simplified view of how it is designed to protect this critical trust boundary.
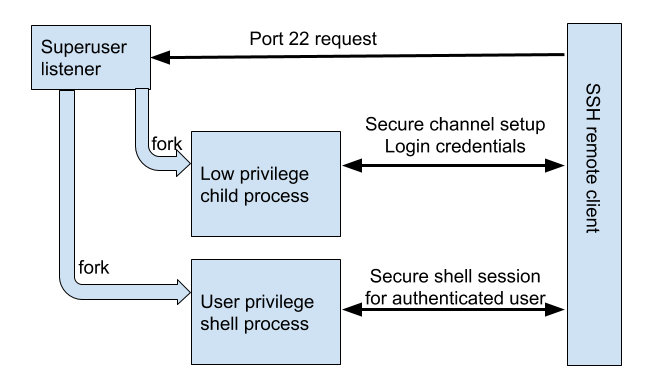
Figure 2-1 How the design of the SSH daemon protects critical trust boundaries
Working from the top, each incoming connection forks a low-privilege child process, which listens on the socket and communicates with the parent (superuser) process. This child process also sets up the protocol’s complex secure-channel encryption and accepts login credentials that it passes to the privileged parent, which decides whether or not to trust the incoming request and grant it a shell. Forking a new child process for each request provides a strategic protection on the trust boundary; it isolates as much of the work as possible, and also minimizes the risk of unintentional side effects building up within the main daemon process. When a user successfully logs in, the daemon creates a new shell process with the privileges of the authenticated user account. When a login attempt fails to authenticate, the child process that handled the request terminates, so it can’t adversely affect the system in the future.
As with assets, you’ll decide when to lump together or split trust levels. In an operating system, the superuser is, of course, the highest level of trust, and some other administrative users may be close enough that you should consider them to be just as privileged. Authorized users typically rank next on the totem pole of trust. Some users may form a more trusted group with special privileges, but usually, there is no need to decide who you trust a little or more or less among them. Guest accounts typically rank lowest in trust, and you should probably emphasize protecting the system from them, rather than protecting their resources.
Web services need to resist malicious client users, so web frontend systems may validate incoming traffic and only forward well-formed requests for service, in effect straddling the trust boundary to the internet. Web servers often connect to more trusted databases and microservices behind a firewall. If money is involved (say, in a credit card processing service), a dedicated high-trust system should handle payments, ideally isolated in a fenced-off area of the datacenter. Authenticated users should be trusted to access their own account data, but you should treat them as very much untrusted beyond that, since anyone can typically create a login. Anonymous public web access represents an even lower trust level, and static public content could be served by machines unconnected to any private data services.
Always conduct transitions across trust boundaries through well-defined interfaces and protocols. You can think of these as analogous to checkpoints staffed by armed guards at international frontiers and ports of entry. Just as the border control agents ask for your passport (a form of authentication) and inspect your belongings (a form of input validation), you should treat the trust boundary as a rich opportunity to mitigate potential attacks.
The biggest risks usually hide in low-to-high trust transitions, like the SSH listener example, for obvious reasons. However, this doesn’t mean you should ignore high-to-low trust transitions. Any time your system passes data to a less-trusted component, it’s worth considering if you’re disclosing information, and if so, if doing so might be a problem. For example, even low-privilege processes can read the hostname of the computer they are running in, so don’t name machines using sensitive information that might give attackers a hint if they attain a beachhead and get code running on the system. Additionally, whenever high-trust services work on behalf of low-trust requests, you risk a denial-of-service attack if the userland requester manages to overtax the kernel.
Identify Threats
Now we begin the work at the heart of threat modeling: identifying potential threats. Working from your model, pore over the parts of the system. The threats will tend to cluster around assets and at trust boundaries, but could potentially lurk anywhere.
I recommend starting with a rough pass (say, from a 10,000-foot view of the system), then coming back later for a more thorough examination (at 1,000 feet) of the more fruitful or interesting parts. Keep an open mind, and be sure to include possibilities even if you cannot yet see exactly how to do the exploit.
Identifying direct threats to your assets should be easy, as well as threats at trust boundaries, where attackers might easily trick trusted components into doing their bidding. Many examples of such threats in specific situations are given throughout this book. Yet you might also find threats that are indirect, perhaps because there is no asset immediately available to harm, nor a trust boundary to cross. Don’t immediately disregard these without considering how these threats might work as part of a chain of events—think of them as bank shots in billiards, or stepping stones that form a path. In order to do damage, an attacker would have to combine multiple indirect threats; or perhaps, paired with bugs or poorly designed functionality, the indirect threats afford openings that give attackers a foot in the door. Even lesser threats might be worth mitigating, depending on how promising they look and how critical the asset at risk may be.
A Bank Vault Example
So far, these concepts may still seem rather abstract, so let’s look at them in context by threat modeling an imaginary bank vault. While reading this walkthrough, focus on the concepts, and if you are paying attention, you should be able to expand on the points I raise (which, intentionally, are not exhaustive).
Picture a bank office in your hometown. Say it’s an older building, with impressive Roman columns framing the heavy solid-oak double doors in front. Built back when labor and materials were inexpensive, the thick, reinforced concrete walls appear impenetrable. For the purpose of this example, let’s focus solely on the large stock of gold stored in the secure vault in the heart of the bank building: this is the major asset we want to protect. We’ll use the building’s architectural drawings as the model, working from a floor plan at 10 foot to 1 inch scale that provides an overview of the layout of the entire building.
The major trust boundary is clearly at the vault door, but there’s another one at the locked door to the employee-only area behind the counter, and a third at the bank’s front door that separates the customer lobby from the exterior. For simplicity, we’ll omit the back door from the model because it’s very securely locked at all times and only opened rarely, when guards are present. This leaves the front door and easily-accessible customer lobby areas as the only significant attack surfaces.
All of this sets the stage for the real work of finding potential threats. Obviously, having the gold stolen is the top threat, but that’s too vague to provide much insight into how to prevent it, so we continue looking for specifics. The attackers would need to gain unauthorized access to the vault in order to steal the gold. In order to do that, they’d need unauthorized access to the employee-only area where the vault is located. So far, we don’t know how such abstract threats could occur, but we can break these down and get more specific. Here are just a few potential threats:
- Observe the vault combination covertly.
- Guess the vault combination.
- Impersonate the bank’s president with makeup and a wig.
Admittedly, these made-up threats are fairly silly, but notice how we developed them from a model, and how we transitioned from abstract threats to concrete ones.
In a more detailed second pass, we now use a model that includes full architectural drawings, the electrical and plumbing layout, and vault design specifications. Armed with more detail, specific attacks are easy to imagine. Take the first threat we just listed: the attacker learning the vault combination. This could happen in several ways. Let’s look at three of them:
- An eagle-eyed robber loiters in the lobby to observe the opening of the vault.
- The vault combination is on a sticky note, visible to a customer at the counter.
- A confederate across the street can watch the vault combination dial through a scope.
Naturally, just knowing the vault combination does not get the intruders any gold. An outsider learning the combination is a major threat, but it’s just one step of a complete attack that must include entering the employee-only area, entering the vault, then escaping with the gold.
Now we can prioritize the enumerated threats and propose mitigations. Here are some straightforward mitigations to each potential attack we’ve identified:
- Lobby loiterer: put an opaque screen in front of the vault.
- Sticky-note leak: institute a policy prohibiting unsecured written copies.
- Scope spy: install opaque, translucent glass windows.
These are just a few of the many possible defensive mitigations. If these types of attacks had been considered during the building’s design, perhaps the layout could have eliminated some of these threats in the first place (for example, by ensuring there was no direct line of sight from any exterior window to the vault area, avoiding the need to retrofit opaque glass).
Real bank security and financial risk management are of course far more complex, but this simplified example shows how the threat modeling process works, including how it propels analysis forward. Gold in a vault is about as simple an asset as it gets, but now you should be wondering, how exactly does one examine a model of a complex software system to be able to see the threats it faces?
Categorizing Threats with STRIDE
In the late 1990s, Microsoft Windows dominated the personal computing landscape. As PCs became essential tools for both businesses and homes, many believed the company’s sales would grow endlessly. But Microsoft had only begun to figure out how networking should work. The Internet (back then still usually spelled with a capital I) and this new thing called the World Wide Web were rapidly gaining popularity, and Microsoft’s Internet Explorer web browser had aggressively gained market share from the pioneering Netscape Navigator. Now the company faced this new problem of security: who knew what can of worms connecting all the world’s computers might open up?
While a team of Microsoft testers worked creatively to find security flaws, the rest of the world appeared to be finding these flaws much faster. After a couple of years of reactive behavior, issuing patches for vulnerabilities that exposed customers over the network, the company formed a task force to get ahead of the curve. As part of this effort, I co-authored a paper with Praerit Garg that described a simple methodology to help developers see security flaws in their own products. Threat modeling based on the STRIDE threat taxonomy drove a massive education effort across all the company’s product groups. More than 20 years later, researchers across the industry continue to use STRIDE, and many independent derivatives, to enumerate threats.
STRIDE focuses the process of identifying threats by giving you a checklist of specific kinds of threats to consider: What can be spoofed (S), tampered (T) with, or repudiated (R)? What information (I) can be disclosed? How could a denial of service (D) or elevation of privilege (E) happen? These categories are specific enough to focus your analysis, yet general enough that you can mentally flesh out details relevant to a particular design and dig in from there.
Though members of the security community often refer to STRIDE as a threat modeling methodology, this is a misuse of the term (to my mind, at least, as the one who concocted the acronym). STRIDE is a simply a taxonomy of threats to software. The acronym provides an easy and memorable mnemonic to ensure that you haven’t overlooked any category of threat. It’s not a complete threat modeling methodology, which would have to include the many other components we’ve already explored in this chapter.
To see how STRIDE works, let’s start with spoofing. Looking through the model, component by component, consider how secure operation depends on the identity of the user (or machine, or digital signature on code, and so on). What advantages might an attacker gain if they could spoof identity here? This thinking should give you lots of possible threads to pull on. By approaching each component in the context of the model from a threat perspective, you can more easily set aside thoughts of how it should work, and instead begin to perceive how it might be abused.
Here’s a great technique I’ve used successfully many times: start your threat modeling session by writing the six threat names on a whiteboard. To get rolling, brainstorm a few of these abstract threats before digging into the details. The term “brainstorm” can mean different things, but the idea here is to move quickly, covering a lot of area, without overthinking it too much or judging ideas yet (you can skip the duds later on). This warm-up routine primes you for what to look out for, and also helps you switch into the necessary mindset. Even if you’re familiar with these categories of threat, it’s worth going through them all, and a couple that are less familiar and more technical bear careful explanation.
Table 2-1 lists six security goals, the corresponding threat categories, and several examples of threats in each category. The security goal and threat category are two sides of the same coin, and sometimes it’s easier to work from one or the other—on the defense (the goal) or the offense (the threat).
Table 2-1 Summary of STRIDE threat categories
| Objective | STRIDE threats | Examples |
|---|---|---|
| Authenticity | Spoofing | Phishing, stolen password, impersonation, message replay, BGP hijacking |
| Integrity | Tampering | Unauthorized data modification and deletion, Superfish ad injection |
| Non-repudiability | Repudiation | Plausible deniability, insufficient logging, destruction of logs |
| Confidentiality | Information disclosure | Leak, side channel, weak encryption, data left behind in a cache, Spectre/Meltdown |
| Availability | Denial of service | Simultaneous requests swamp a web server, ransomware, MemCrashed |
| Authorization | Elevation of privilege | SQL injection, xkcd’s “Little Bobby Tables” |
Half of the STRIDE menagerie are direct threats to the information security fundamentals you learned about in Chapter 1: information disclosure is the enemy of confidentiality, tampering is the enemy of integrity, and denial of service compromises availability. The other half of STRIDE targets the Gold Standard. Spoofing subverts authenticity by assuming a false identity. Elevation of privilege subverts proper authorization. That leaves repudiation as the threat to auditing, which may not be immediately obvious and so is worth a closer look.
According to the Gold Standard, we should maintain accurate records of critical actions taken within the system and then audit those actions. Repudiation occurs when someone credibly denies that they took some action. In my years working in software security, I have never seen anyone directly repudiate anything (nobody has ever yelled “Did so!” and “Did not!” at each other in front of me). But what does happen is, say, a database suddenly disappears, and nobody knows why, because nothing was logged, and the lost data is gone without a trace. The organization might suspect that an intrusion occurred. Or it could have been a rogue insider, or possibly a regrettable blunder by an administrator. But absent any evidence, nobody knows. That’s a big problem, because if you cannot explain what happened after an incident, it’s very hard to prevent it from happening again. In the physical world, such perfect crimes are rare because activities such as robbing a bank involve physical presence, which inherently leaves all kinds of traces. Software is different; unless you provide a means to reliably collect evidence and log events, no fingerprints or muddy boot tracks remain as evidence.
Typically, we mitigate the threat of repudiation by running systems in which administrators and users understand they are responsible for their actions, because they know an accurate audit trail exists. This is also one more good reason to avoid having admin passwords written on a sticky note that everyone shares. If you do that, when trouble happens, everyone can credibly claim someone else must have done it. This applies even if you fully trust everyone, because accidents happen, and the more evidence you have available when trouble arises, the easier it is to recover and remediate.
STRIDE at the Movies
Just for fun (and to solidify these concepts), consider the STRIDE threats applied to the plot of the film Ocean’s Eleven. This classic heist story nicely demonstrates threat modeling concepts, including the full complement of STRIDE categories, from the perspectives of both attacker and defender. Apologies for the simplification of the plot, which I’ve done for brevity and focus, as well as for spoilers.
Danny Ocean violates parole (an elevation of privilege), flies out to meet his old partner in crime, and heads for Vegas. He pitches an audacious heist to a wealthy casino insider, who fills him in on the casino’s operational details (information disclosure), then gathers his gang of ex-cons. They plan their operation using a full-scale replica vault built for practice. On the fateful night, Danny appears at the casino and is predictably apprehended by security, creating the perfect alibi (repudiation of guilt). Soon he slips away through an air duct, and through various intrigues he and his accomplices extract half the money from the vault (tampering with its integrity), exfiltrating their haul with a remote-control van.
Threatening to blow up the remaining millions in the vault (a very expensive denial of service), the gang negotiates to keep the money in the van. The casino owner refuses and calls in the SWAT team, and in the ensuing chaos the gang destroys the vault’s contents and gets away. After the smoke clears, the casino owner checks the vault, lamenting his total loss, then notices a minor detail that seems amiss. The owner confronts Danny—who is back in lockup, as if he had never left—and we learn that the SWAT team was, in fact, the gang (spoofing by impersonating the police), who walked out with the money hidden in their tactical equipment bags after the fake battle. The practice vault mock-up had provided video to make it only appear (spoofing of the location) that the real vault had been compromised, which didn’t actually happen until the casino granted full access to the fake SWAT team (an elevation of privilege for the gang). Danny gets the girl, and they all get away clean with the money—a happy ending for the perpetrators that might have turned out quite differently had the casino hired a threat modeling consultant!
Mitigate Threats
At this stage, you should have a collection of potential threats. Now you need to assess and prioritize them to best guide an effective defense. Since threats are, at best, educated guesses about future events, all of your assessments will contain some degree of subjectivity.
What exactly does it mean to understand threats? There is no easy answer to this question, but it involves refining what we know, and maintaining a healthy skepticism to avoid falling into the trap of thinking that we have it all figured out. In practice, this means quickly scanning to collect a bunch of mostly abstract threats, then poking into each one a little further to learn more. Perhaps we will see one or two fairly clear-cut attacks, or parts of what could constitute an attack. We elaborate until we run up against a wall of diminishing returns.
At this point, we can deal with the threats we’ve identified in one of four ways:
- Mitigate the risk by either redesigning or adding defenses to reduce its occurrence or lower the degree of harm to an acceptable level.
- Remove a threatened asset if it isn’t necessary, or, if removal isn’t possible, seek to reduce its exposure or limit optional features that increase the threat.
- Transfer the risk by offloading responsibility to a third party, usually in exchange for compensation. (Insurance, for example, is a common form of risk transfer, or the processing of sensitive data could be outsourced to a service with a duty to protect confidentiality.)
- Accept the risk, once it is well understood, as reasonable to incur.
Always attempt to mitigate any significant threats, but recognize that results are often mixed. In practice, the best possible solution isn’t always feasible, for many reasons: a major change might be too costly, or you may be stuck using an external dependency beyond your control. Other code might also depend on vulnerable functionality, such that a fix might break things. In these cases, mitigation means doing anything that reduces the threat. Any kind of edge for defense helps, even a small one.
Ways to do partial mitigation include:
– Make harm less likely to occur — For example, make it so the attack only works 10 percent of the time.
– Make harm less severe — For example, make it so only a small part of the data can be destroyed.
– Make it possible to undo the harm — For example, ensure that you can easily restore any lost data from a backup.
– Make it obvious that harm occurred — Use tamper-evident packaging that makes it easy to detect a modified product, protecting consumers. (In software, good logging helps here.)
Much of the remainder of the book is about mitigation: how to design software to minimize threats, and what strategies and secure software patterns are useful for devising mitigations of various sorts.
Privacy Considerations
Privacy threats are just as real as security threats, and they require separate consideration in a full assessment of threats to a system, because they add a human element to the risk of information disclosure. In addition to possible regulatory and legal considerations, personal information handling may involve ethical concerns, and it’s important to honor stakeholder expectations.
If you’re collecting personal data of any kind, you should take privacy seriously as a baseline stance. Think of yourself as a steward of people’s private information. Strive to stay mindful of your users’ perspective, including careful consideration of the wide range of privacy concerns they might have, and err on the side of care. It’s easy for builders of software to discount how sensitive personal data can be when they’re immersed in the logic of system building. What in code looks like yet another field in a database schema could be information that, if leaked, has real consequences for an actual person. As modern life increasingly goes digital, and mobile computing becomes ubiquitous, privacy will depend more and more on code, potentially in new ways that are difficult to imagine. All this is to say that you would be smart to stay well ahead of the curve by exercising extreme vigilance now.
A few very general considerations for minimizing privacy threats include the following:
- Assess privacy by modeling scenarios of actual use cases, not thinking in the abstract.
- Learn what privacy policies or legal requirements apply, and follow the terms rigorously.
- Restrict the collection of data to only what is necessary.
- Be sensitive to the possibility of seeming creepy.
- Never collect or store private information without a clear intention for its use.
- When information already collected is no longer used or useful, proactively delete it.
- Minimize information sharing with third parties (which, if it occurs, should be well documented).
- Minimize disclosure of sensitive information—ideally this should be done only on a need-to-know basis.
- Be transparent, and help end users understand your data protection practices.
Threat Modeling Everywhere
The threat modeling process described here is a formalization of how we navigate in the world; we manage risk by balancing it against opportunities. In a dangerous environment, all living organisms make decisions based on these same basic principles. Once you start looking for it, you can find instances of threat modeling everywhere.
When expecting a visit from friends with a young child, we always take a few minutes to make special preparations. Alex, an active three-year-old, has an inquisitive mind, so we go through the house “child-proofing.” This is pure threat modeling, as we imagine the threats by categories—what could hurt Alex, what might get broken, what’s better kept out of view of a youngster—then look for assets that fit these patterns. Typical threats include a sharp letter opener, which he could stick in a wall socket; a fragile antique vase that he might easily break; or perhaps a coffee-table book of photography that contains images inappropriate for children. The attack surface is any place reachable by an active toddler. Mitigations generally consist of removing, reducing, or eliminating points of exposure or vulnerability: we could replace the fragile vase with a plastic one that contains just dried flowers, or move it up onto a mantlepiece. People with children know how difficult it is to anticipate what they might do. For instance, did we anticipate Alex might stack up enough books to climb up and reach a shelf that we thought was out of reach? This is what threat modeling looks like outside of software, and it illustrates why preemptive mitigation can be well worth the effort.
Here are a few other examples of threat modeling you may have noticed in daily life:
- Stores design return policies specifically to mitigate abuses such as shoplifting and then returning the product for store credit, or wearing new apparel once and then returning it for a refund.
- Website terms-of-use agreements attempt to prevent various ways that users might maliciously abuse the site.
- Traffic safety laws, speed limits, driver licensing, and mandatory auto insurance requirements are all mitigation mechanisms to make driving safer.
- Libraries design loan policies to mitigate theft, hoarding, and damage to the collection.
You can probably think of lots of ways that you apply these techniques too. For most of us, when we can draw on our physical intuitions about the world, threat modeling is remarkably easy to do. Once you recognize that software threat modeling works the same way as your already well-honed skills in other contexts, you can begin to apply your natural capabilities to software security analysis, and quickly raise your skills to the next level.
✺ ✺ ✺ ✺ ✺ ✺ ✺ ✺